
Annotation statistics
Label Studio Enterprise Edition includes various annotation and labeling statistics. The open source Community Edition of Label Studio does not perform these statistical calculations. If you're using Label Studio Community Edition, see Label Studio Features to learn more.
Annotation statistics help you determine the quality of your dataset, its readiness to be used to train models, and assess the performance of your annotators and reviewers.
Task agreement
Task agreement shows the consensus between multiple annotators when labeling the same task. There are several types of task agreement in Label Studio Enterprise:
- a per-task agreement score, visible on the Data Manager page for a project. This displays how well the annotations on a particular task match across annotators.
- an inter-annotator agreement matrix, visible on the Members page for a project. This displays how well the annotations from specific annotators agree with each other in general, or for specific tasks.
You can also see how the annotations from a specific annotator compare to the prediction scores for a task, or how they compare to the ground truth labels for a task.
For more about viewing agreement in Label Studio Enterprise, see Verify model and annotator performance.
Agreement method
The agreement method defines how agreement scores across all annotations for a task are combined to form a single inter-annotator agreement score. Label Studio uses the mean average of all inter-annotation agreement scores for each annotation pair as the final task agreement score.
Review the diagram for a full explanation:
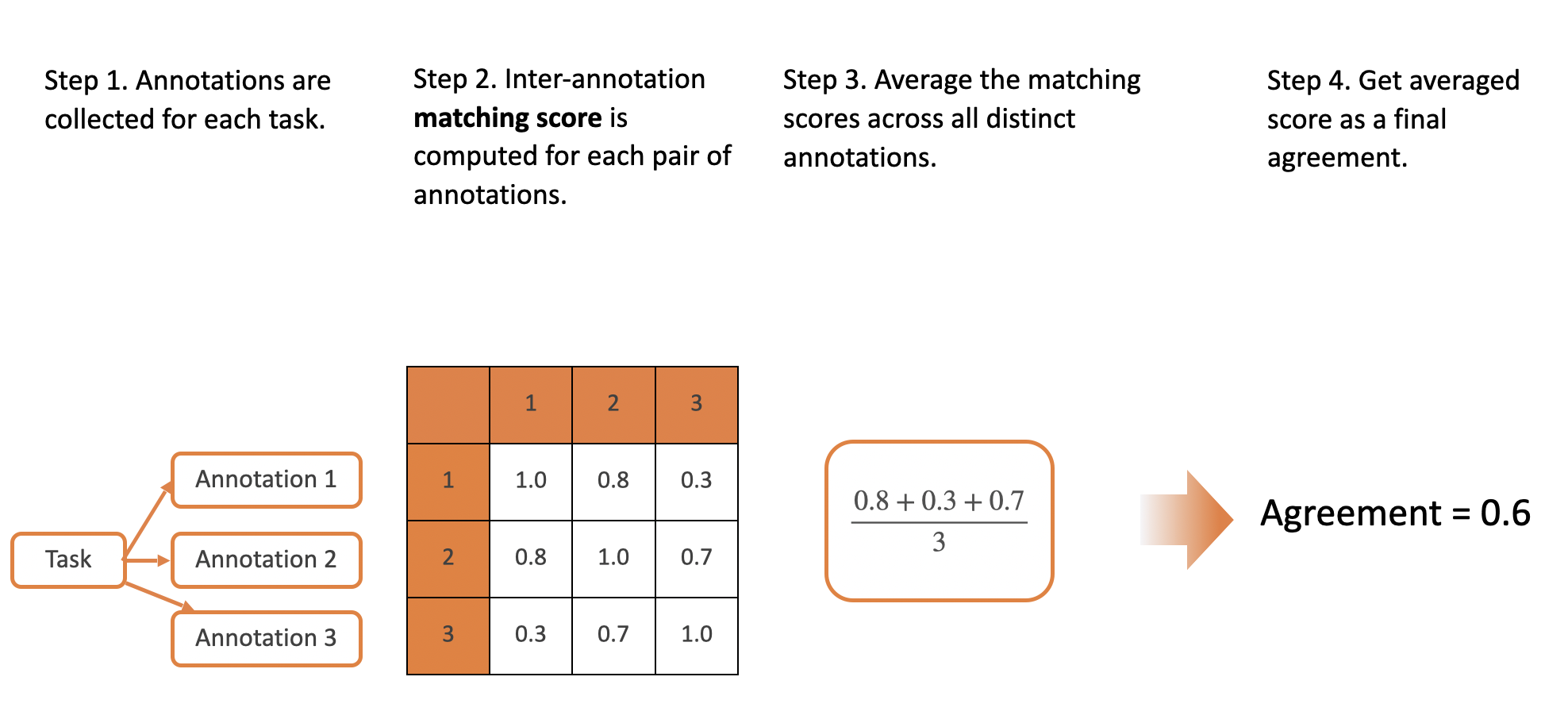
Example
One annotation that labels the text span “Excellent tool” as “positive”, a second annotation that labels the span “tool” as “positive”, and a third annotation that labels the text span “tool” as “negative”.

The agreement score for the first two annotations is 50%, based on the intersection of the text spans. The agreement score comparing the second annotation with the third annotation is 0%, because the same text span was labeled differently.
The task agreement conditions use a threshold of 40% to group annotations based on the agreement score, so the first and second annotations are matched with each other, and the third annotation is considered mismatched. In this case, task agreement exists for 2 of the 3 annotations, so the overall task agreement score is 67%.
Agreement score
Depending on the type of labeling that you perform, you can select a different type of agreement metric to use to calculate the agreement score used in task agreement statistics. See how to Define the agreement metric for annotation statistics.
The agreement score assesses the similarity of annotations for a specific task.
Available agreement metrics
The following table lists the agreement metrics available in Label Studio Enterprise. If you want to use a different agreement metric, you can create a custom agreement metric.
| Agreement Metric | Tag | Labeling Type | Description |
|---|---|---|---|
| Basic matching function | All tags | All types | Performs the default evaluation function for each control tag. |
| Exact matching | All tags | All types | Evaluates whether annotation results exactly match, ignoring any label weights. |
| Custom agreement metric | All tags | All types | Performs the evaluation function that you define. See create a custom agreement metric. |
| Exact matching choices | Choices | Categorical, Classification | Evaluates whether annotations exactly match, considering label weights. |
| Choices per span region | Choices | Categorical, Classification | Evaluates whether specific choices applied to specific text spans match. |
| Choices per hypertext span region | Choices | Categorical, Classification | Evaluates whether specific choices applied to specific hypertext spans match. |
| Choices per bbox region | Choices | Bounding Boxes, Categorical, Classification | Evaluates whether specific choices applied to specific bounding box regions match. |
| Precision on Choices per bbox region | Choices | Bounding Boxes, Categorical, Classification | Evaluates the precision of specific choices applied to specific bounding box regions. |
| Recall on Choices per bbox region | Choices | Bounding Boxes, Categorical, Classification | Evaluates the recall of specific choices applied to specific bounding box regions. |
| F1 on Choices per bbox region | Choices | Bounding Boxes, Categorical, Classification | Evaluates the F1, or F-score, of specific choices applied to specific bounding box regions. |
| Choices per polygon region | Choices | Polygons, Categorical, Classification | Evaluates whether specific choices applied to specific polygon regions match. |
| Precision on Choices per polygon region | Choices | Polygons, Categorical, Classification | Evaluates the precision of specific choices applied to specific polygon regions. |
| Recall on Choices per polygon region | Choices | Polygons, Categorical, Classification | Evaluates the recall of specific choices applied to specific polygon regions. |
| F1 on Choices per polygon region | Choices | Polygons, Categorical, Classification | Evaluates the F1, or F-score, of specific choices applied to specific polygon regions. |
| Intersection over 1D regions | Labels | Semantic Segmentation, Named Entity Recognition | Evaluates whether two given one-dimensional labeled regions have points in common. |
| Percentage of matched spans by IOU w.r.t threshold | Labels | Semantic Segmentation, Named Entity Recognition | Evaluates the percentage by which two given labeled regions overlap compared to the union (IOU) of the regions, and compare the IOU to a threshold. |
| Common subtree matches | Taxonomy | Categorization, Classification | Evaluates common subtree matches for a taxonomy of choices. |
| Common labels matches | Taxonomy | Categorization, Classification, Named Entity Recognition | Evaluates common label matches for a taxonomy of labels assigned to regions. |
| Intersection over 1D spans without labels | Region | Image Segmentation, Computer Vision | Evaluates whether two given one-dimensional regions have points in common. |
| Percentage of matched spans without labels by IOU w.r.t threshold | Region | Image Segmentation, Object Detection | Evaluates the percentage by which two given regions overlap compared to the union (IOU) of the regions, and compare the IOU to a threshold. |
| Text edit distance | TextArea | Transcription | Uses the edit distance algorithm to calculate how dissimilar two text annotations are to one another. |
| Text edit distance per span region | TextArea | Text | Uses the edit distance algorithm to calculate how dissimilar two text spans are to one another. |
| Text edit distance per span region, with percentage of matched spans by IOU w.r.t threshold | TextArea | Text | Uses the edit distance algorithm to calculate how dissimilar two text spans are to one another, then calculate the percentage of overlap compared to the union (IOU) of matching spans and compare the IOU to a threshold. |
| Text edit distance per hypertext span region, with percentage of matched spans by IOU w.r.t threshold | TextArea | Hypertext | Uses the edit distance algorithm to calculate how dissimilar two text spans are to one another, then calculate the intersection over union (IOU) for the percentage of matching spans and compare the IOU to a threshold. |
| Text edit distance per bbox region | TextArea | Optical character recognition (OCR) with bounding boxes | Uses the edit distance algorithm to calculate how dissimilar two text areas are to each other for each bounding box region they are associated with. |
| Text edit distance per polygon region | TextArea | OCR with polygons | Uses the edit distance algorithm to calculate how dissimilar two text areas are to each other for each polygonal region they are associated with. |
| OCR distance | Rectangle | Optical Character Recognition | Uses the edit distance algorithm to calculate how dissimilar two text areas are to each other for each rectangular region they are associated with. |
| Intersection over HTML spans | HyperTextLabels | HTML | Evaluates whether two given hypertext spans have points in common. |
| Percentage of matched spans by IOU w.r.t threshold | HyperTextLabels | HTML | Evaluates the percentage by which two given hypertext regions overlap compared to the union (IOU) of the regions, and compare the IOU to a threshold. |
| Intersection over Paragraphs | ParagraphLabels | Dialogue, Text | Evaluates whether two given one-dimensional paragraph-labeled spans have points in common. |
| Percentage of matched spans by IOU w.r.t threshold | ParagraphLabels | Dialogue, Text | Evaluates the percentage by which two given paragraph-labeled regions overlap compared to the union (IOU) of the regions, and compare the IOU to a threshold. |
| Average precision for ranking | Ranker | All types | Calculates the precision for the ranking. |
| IOU for bounding boxes | RectangleLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two bounding box regions. |
| Precision at specific IOU threshold for bounding boxes | RectangleLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two bounding box regions, then computes the precision for the values above a threshold. |
| Recall at specific IOU threshold for bounding boxes | RectangleLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two bounding box regions, then computes the recall for the values above a threshold. |
| F1 score at specific IOU threshold for bounding boxes | RectangleLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two bounding box regions, then computes the F1-score for the values above a threshold. |
| IOU for polygons | PolygonLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two polygonal regions. |
| Precision at specific IOU threshold for polygons | PolygonLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two polygonal regions, then computes the precision for the values above a threshold. |
| Recall at specific IOU threshold for polygons | PolygonLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two polygonal regions, then computes the recall for the values above a threshold. |
| F1 score at specific IOU threshold for polygons | PolygonLabels | Object Detection, Semantic Segmentation | Evaluates the overlap compared to the union (IOU) of two polygonal regions, then computes the F1-score for the values above a threshold. |
| KeyPoint agreement metric | KeyPointLabels | Computer Vision | Evaluates whether key point annotations match. |
| Intersection over 1D timeseries spans | TimeSeriesLabels | Time Series | Evaluates whether two given one-dimensional time series spans have points in common. |
| Exact matching pairwise comparison | Pairwise | Comparison | Evaluates whether the results exactly match. |
| Exact matching rating | Rating | Evaluation, Rating | Evaluates the ratings assigned to tasks exactly match. |
Basic matching function
Performs the default evaluation function for each control tag. For example for TextArea tag Edit distance metric is used.
Exact matching
For example, for two given annotations x and y, an agreement metric that performs a naive comparison of the results works like the following:
- If both
xandyare empty annotations, the agreement score is1. - If
xandyshare no similar points, the agreement score is0. - If different labeling types are used in
xandy, the partial agreement scores for each data labeling type are averaged.
Exact matching choices example
For data labeling tasks where annotators select a choice, such as image or text classification, or data labeling tasks where annotators select a rating, you can select the Exact matching choices agreement metric. For this function, the agreement score for two given task annotations x and y is computed as follows:
- If
xandyare the same choice, the agreement score is1. - If
xandyare different choices, the agreement score is0.
When calculating agreement between selected choices conditional on a specific region, such as when perRegion="true" attribute is specified for the <Choices> tag, corresponding choice agreement is multiplied with region agreements.
For example, calculating intersection over union with two bounding boxes and corresponding choice selections:
- The IoU for the bounding box annotations results in an agreement score of 0.9.
- The conditional choices selected do not match, so that agreement score is 0.
- As a result, the final agreement score for these two annotations is 0 (0.9 * 0 = 0).
Edit distance algorithm example
For data labeling tasks where annotators transcribe text in a text area, the resulting annotations contain a list of text.
You can select agreement metrics based on the intersection over one-dimensional text spans such as splitting the text area by words or characters, or using an edit distance algorithm. Decide what method to use to calculate the agreement score based on your use case and how important precision is for your data labels.
The agreement score for two given task annotations x and y is computed as follows:
- The list of text items in each annotation is indexed, such that
x = [x1, x2, ..., xn]and similarly,y = [y1, y2, ..., yn]. - For each aligned pair of text items across the two annotations
(x1, y1)the similarity of the text is calculated. - For each unaligned pair, for example, when one list of text is longer than the other, the similarity is zero.
- The similarity scores are averaged across all pairs, and the result is the agreement score for the task.
The following text edit distance algorithms are available:
- Levenshtein
- Damerau-Levenshtein
- Hamming
- MLIPNS
- Jaro-Winkler
- Strcmp95
- Needleman-Wunsch
- Smith-Waterman
Intersection over Union example
The Intersection over Union (IoU) metric compares the area of overlapping regions, such as bounding boxes, polygons or textual / time series one-dimensional spans with the overall area, or union, of the regions.
For example, for two annotations x and y containing either bounding boxes or polygons, the following calculation occurs:
- LSE identifies whether any regions overlap across the two annotations. Overlapping can be only considered with matched labels.
- For each pair of overlapping regions across the annotations, the area of the overlap, or intersection
aIis compared to the combined areaaUof both regions, referred to as the union of the regions:aI÷aU - The average of
aI÷aUfor each pair of regions is used as the IoU calculation for a pair of annotations, or each IoU calculation for eadch label or region is used.
For example, if there are two bounding boxes for eachxandyannotations, the agreement ofxandy= ((aI÷aU) + (aI÷aU)) ÷2 .
Intersection over union with text
For data labeling tasks where annotators assign specific labels to text spans in text, hypertext, or paragraphs of dialogue, the agreement score is calculated by comparing the intersection of annotations over the result spans, normalized by the length of each span.
For two given task annotations x and y, the agreement score formula is m(x, y) = spans(x) ∩ spans(y)
- For text annotations, the span is defined by the
startandendkeys. - For hypertext annotations, the span is defined by the
startOffsetandendOffsetkeys. - For paragraphs of dialogue annotations, the span is defined by the
startOffsetandendOffsetkeys.
Intersection over union with other metrics
The IoU metric can be combined with other metrics. Several metrics in Label Studio Enterprise use IoU to establish initial agreement across annotations, then computes the precision, recall, or F1-score for the IoU values above a specific threshold. Text IoU can also include the edit distance algorithm.
Intersection over union with threshold
You can use IoU with a threshold to calculate agreement. With a threshold you can consider only the regions that are most similar to each other.
In this case, the same IoU metric of aI ÷ aU is calculated, but only the percentage of those above a threshold, say 0.5, are considered for the final agreement score. For example:
IoU for regions x1 and y1: aI ÷ aU = 0.99
IoU for regions x2 and y2: aI ÷ aU = 0.34
IoU for regions x3 and y3: aI ÷ aU = 0.82
Number of region pairs with IoU above the threshold of 0.5 = 2 of 3
Agreement of x and y = 0.66
Intersection over one dimension example
The intersection over one dimension metric is similar to the exact matching choices. This metric evaluates whether two given spans or regions have points in common.
For example, for given one dimensional annotations x and y, identify whether any points are common between the annotations:
- Identify the list of points for annotation
xand the list of points for annotationy. - Compare the two lists.
- Compare the total number of points in common against the total number of points, for example, 8 common points and 10 total points across the annotations.
- The resulting comparison is the agreement score for the annotations. For example,
0.80.
Precision example
For a given set of annotations, this agreement metric compares the number of true positives with the total number of positive results from the annotations.
Precision is calculated for IoU with a threshold like the following example using an annotation x and an annotation y:
- Calculate the IoU for all relevant pairs of regions:
IoU for regions x1 and y1:aI÷aU= 0.99, both labeledCar
IoU for regions x2 and y2:aI÷aU= 0.34, both labeledCar
IoU for regions x3 and y3:aI÷aU= 0.82, x3 labeledCar, y3 labeledAirplane
IoU for regions x4 and y4:aI÷aU= 0.44, x3 labeledCar, y3 labeledAirplane
IoU for regions x5 and y5:aI÷aU= 0.67, x5 labeledCar, y5 labeledAirplane - Determine which labels are assigned to each region.
- For each pair of regions, determine whether the labels match and whether the IoU is above a threshold of 0.5.
- True positive (TP) annotated regions are those with IoU values above the threshold and with matching labels. TP = 1, because x1 and y1 match and have an IoU above the threshold.
- False positive (FP) regions are those where the labels do not match but the IoU values are above the threshold. FP = 2, because x3 and y3 do not match but the IoU value is above the threshold, and the same is true for x5 and y5.
- Precision is calculated as TP ÷ (TP + FP), in this case, 1/3, or
0.33.
Recall example
For a given set of annotations, this agreement metric compares the number of true positives with the total number of true positives and false negatives in the annotation results.
Recall is calculated for IoU with a threshold like the following example using an annotation x and an annotation y:
- Calculate the IoU for all relevant pairs of regions:
IoU for regions x1 and y1:aI÷aU= 0.99, both labeledCar
IoU for regions x2 and y2:aI÷aU= 0.34, both labeledCar
IoU for regions x3 and y3:aI÷aU= 0.82, x3 labeledCar, y3 labeledAirplane
IoU for regions x4 and y4:aI÷aU= 0.44, x4 labeledCar, y4 labeledAirplane
IoU for regions x5 and y5:aI÷aU= 0.67, x5 labeledCar, y5 labeledAirplane - Determine which labels are assigned to each region.
- For each pair of regions, determine whether the labels match and whether the IoU is above a threshold of 0.5.
- True positive (TP) annotated regions are those with IoU values above the threshold and with matching labels. TP = 1, because x1 and y1 match and have an IoU above the threshold.
- False negative (FN) annotated regions are those with IoU values below the threshold, but the labels still match. FN = 1, because x2 and y2 match, but the IoU is below the threshold.
- Recall is calculated as TP ÷ (TP + FN), in this case, 1/2, or
0.5.
F1 score example
For a given set of annotations, this agreement metric compares the precision and recall for two annotations using the following formula:
F1 = 2 * (precision * recall) ÷ (precision + recall)
The F1-score is calculated for IoU with a threshold like the following example using an annotation x and an annotation y:
- Calculate the IoU for all relevant pairs of regions:
IoU for regions x1 and y1:aI÷aU= 0.99, both labeledCar
IoU for regions x2 and y2:aI÷aU= 0.34, both labeledCar
IoU for regions x3 and y3:aI÷aU= 0.82, x3 labeledCar, y3 labeledAirplane
IoU for regions x4 and y4:aI÷aU= 0.44, x4 labeledCar, y5 labeledAirplane
IoU for regions x5 and y5:aI÷aU= 0.67, x5 labeledCar, y5 labeledAirplane - Determine which labels are assigned to each region.
- For each pair of regions, determine whether the labels match and whether the IoU is above a threshold of 0.5.
- True positive (TP) annotated regions are those with IoU values above the threshold and with matching labels. TP = 1, because x1 and y1 match and have an IoU above the threshold.
- False positive (FP) regions are those where the labels do not match but the IoU values are above the threshold. FP = 2, because x3 and y3 do not match but the IoU value is above the threshold, and the same is true for x5 and y5.
- False negative (FN) annotated regions are those with IoU values below the threshold, but the labels still match. FN = 1, because x2 and y2 match, but the IoU is below the threshold.
- Precision is calculated as TP ÷ (TP + FP), in this case, 1/3, or
0.33. - Recall is calculated as TP ÷ (TP + FN), in this case, 1/2, or
0.5.
For x and y annotations in this case, the F1-score =
2 * ((0.33 * 0.5) ÷ (0.33 + 0.5)) = 0.40Common matches taxonomy example
This metric applies for classification and taxonomy tasks. It looks at which items are selected, and if matching items are selected, counts the number of common items and compares them to the total number of selected items across both annotations.
For annotations x and y, if x has 3 selections in common with y out of a possible 4 selections, the agreement score is 0.75 because 3 of 4 possible selections match. This can happen for example if the first three options in a boolean classification task with three layers of nested options, but the fourth subtree option is different.

If you found an error, you can file an issue on GitHub!